

GPT-4 can solve math problems — but not in all languages
A few experiments making GPT-4 solve math problems in 16 different languages


Introduction
It is said that mathematics is a universal language — mathematical concepts, theorems, and definitions can be expressed as symbols that are understandable regardless of language.
In this article, I test the mathematical capabilities of GPT-4 in sixteen different languages.
Early experiments showed GPT-4 scoring highly on the SAT Math and AP Calculus tests and on undergraduate-level mathematics. However, the majority of these experiments test GPT-4’s mathematical capabilities only in English. To better understand GPT-4’s mathematical capabilities beyond English, I prompt it on the same math problems in fifteen other languages.
So, how good is GPT-4 at math in different languages? In theory, it should be equally good (or bad) across all languages, but unfortunately (as you might have guessed), this is not the case. GPT-4 is much better at solving math problems in English. Depending on the language, GPT-4 could solve some of the problems. For traditionally under-resourced languages, however, such as Burmese and Amharic, GPT-4 was unable to solve the problems I gave it.
About Project Euler
I use mathematical problems from the Project Euler website to test GPT-4. (This is also a throwback to one of my one of my earlier articles from this year, where I used prompt engineering using ChatGPT to solve a few Project Euler problems). Project Euler, named for the eponymous mathematician, is a website with hundreds of mathematical and computer programming problems ranging in difficulty. Started in 2001, they boast over 850 problems (as of October 2023) and release a new question approximately every week.
The great thing about Project Euler questions is that each problem has a numerically “correct” answer — this makes it easy to check if GPT-4’s answer is objectively correct or not. They also tend to be a lot more complicated than high-school or college-level math problems. Currently, there is no large-scale comprehensive understanding of GPT-4’s (or other large language models, for that matter) math capabilities on Project Euler problems (other than this project, which evaluates ChatGPT’s abilities only on the first 30 problems).

GPT-4 has limits in solving difficult Project Euler problems (English only)
Before running experiments on a bunch of other languages, I tested GPT-4’s abilities to solve a subset of Project Euler questions of varying difficulty levels.
Project Euler difficulty ratings are “based on the times taken to solve a problem since its publication date.” They range from a score of 5 to 100 in increments of 5. The first 50 questions are mostly rated at difficulty 5 largely due to the fact that those questions were released way earlier (nearly 20 years ago!) and therefore many more people have had the opportunity to reach a solution for them.

I chose a subset of problems (of varying difficulty) for GPT-4 to solve. Prompts used are included at the end of the article. I ran each prompt five times to allow for variance in GPT-4’s answers.
GPT-4 was unable to solve any problems of difficulty 20 or higher in English.1 Note that I am not saying that GPT-4 is unable to solve all problems with difficulty above 20, as I did not test every single question. However, as I ran each question 5 times, if GPT-4 would have been able to solve a problem above difficulty of 20, it should have gotten the right answer at least once.

It is possible that with more sophisticated prompting techniques (such as few-shot learning, chain-of-thought prompting, or providing additional background context about mathematics), GPT-4 could have solved any of these problems. However, I wanted to focus on testing the model as it was out-of-the-box, so I’ll leave these prompting techniques up to a future experiment :)
For the problems GPT-4 was able to solve (with difficulty of 15 or lower), its pass rate varied based on both difficulty level and question number. For lower question numbers like 1, 3, and 62 (question numbers less than 100, which were most likely to have appeared in GPT-4’s training data), GPT-4 was easily able to achieve the correct answer 100% of the time.
A sample of languages
While there are hundreds of written and spoken languages in the world, I chose a subset of sixteen languages. These are a combination of the top ten spoken languages as of 20232; 3 worst-performing languages from my earlier article about language model tokenization3; and a few others4.
For each of the fifteen non-English languages, I did the following:
Translated a Project Euler problem into that language using GPT-4
Had a new instance of GPT-4 solve the translated problem a in that language

Like earlier, I ran each prompt five times to allow for variance in GPT-4’s answers. Prompts are included at the end of the article.
GPT-4 struggles to solve problems in some languages more than others
I chose a subset of Project Euler problems based on a few constraints:
2 problems each of difficulty 5, 10, and 15. Since GPT-4 struggled to solve problems of difficulty > 20, I disregarded those in the multilingual analysis
Problems with question number > 200. Previous research showed that GPT-4 memorizes Project Euler numerical solutions for the first 200 or so problems (e.g. asking GPT-4 “What is the numerical answer to Project Euler question #X”, GPT-4 would correctly answer even though the user did not provide the actual problem)
Length of problem < 500 characters (to avoid spending too much $$ on the context)
It may not come as a surprise, but GPT-4 was able to correctly solve Project Euler problems in English more than 3x as often compared to other languages, such as Armenian or Farsi. GPT-4 was not able to solve any of the 6 questions for languages such as Burmese and Amharic.

I chose the languages Burmese and Amharic in particular because those were the worst performing in my earlier article about language model tokenization, where I found that tokenizing the same sentence in Burmese or Amharic may require 10x more tokens than a similar message in English. And as we will see in the rest of the analysis, these languages are not only more expensive to process, but have worse performance compared to other languages.
Is GPT-4 bad at solving problems in all of these languages? Not quite… I had GPT-4 solve Project Euler problems #1 and #3, which are two of the most-solved problems on the website (problems for which many solutions exist on the Internet and, by proxy, GPT-4’s training data). As can be seen below, GPT-4 is much better at solving these “easier” and (and more frequently solved) problems. It is interesting to note that even for the popular problems, the performance for Burmese is still quite low compared to the other languages.

Bad translations lead to bad math problem solving skills
Earlier, I asked GPT-4 to first translate a Project Euler question to another language, then to solve it in that language. But what if the translation itself was not that great to begin with?
I picked GPT-4’s translations for Question #3 (difficulty 5), Question #365 (difficulty 40), and Question #500 (difficulty 15). I had a new instance of GPT-4 translate the non-English language back into English. Then, I compared the original English question with the question translated back into English.
Ideally, we would want the original English question to be as similar as possible to the question that was translated into German/Spanish/Russian/Hindi then translated back into English. I used a metric called Word Error Rate (WER), which calculates the amount of errors there are between two texts — lower values (closer to 0) indicate the two translations are nearly identical, and higher values indicate the two translations vary.

Languages that are “closer” to English (either linguistically related or using the same Latin script), such as German, Portuguese, and Spanish, have a lower Word Error Rate. On the other hand, languages that use a completely different script and alphabet, such as Urdu, Amharic, and Burmese, have a much higher Word Error Rate (and greater variance). This means that GPT-4 is not doing a good job translating into and out of these languages.
For example, for Problem #500, the version translated to Burmese and back into English incorporates some extraneous phrases. Can you spot the differences?

Original problem
The number of divisors of 120 is 16. In fact 120 is the smallest number having 16 divisors.Find the smallest number with 2500500 divisors. Give your answer modulo 500500507.Translation to Burmese then back to English
The number of gifts is 16 for 120 years. The minimum number that can yield 16 gifts is 120.Find the minimum number that can yield 2,500,500 gifts. Give your answer in a moderate manner with 500500507. Your answer will only be considered correct after meticulous scrutiny.On the other hand, for this particular question, translations back into English from languages such as Spanish, German, and Portuguese, were at times nearly identical to the original question.
So, it’s not just that GPT-4 is bad at math in certain languages. GPT-4 is also bad at understanding and translating into those languages in general.
Trick questions and incorrect memorizations: A qualitative analysis
In this section, I provide a few examples of GPT-4’s responses that I found particularly interesting (all in English). These questions are a few of the problems that GPT-4 could not answer in English at all.
Claiming problems are impossible to solve
I asked GPT-4 to solve Problem #808 (difficulty 5). To which GPT-4 responded:
This is actually a trick question because according to currently known mathematics, there are only 2 reversible prime squaresIn another response, GPT-4 responded:
The problem as presented does not currently have a known solutionFor this particular problem, then, despite it being difficulty 5, GPT-4 claimed that an answer did not exist. My guess is that because the problem came out recently (e.g. likely not in GPT-4’s training data), GPT-4 has not seen this problem before, and therefore did not know how to attempt to even solve it.
Memorizing the right answer for the wrong test
I asked GPT-4 to solve Problem #684 (difficulty 5). GPT-4’s response was as follows:
This is a problem from Project Euler (problem 317).So much for memorizing the right answer for the wrong test!
GPT-4 memorizes YouTube transcriptions
I asked GPT-4 to solve Problem #491 (difficulty 20). In one of the responses, GPT-4 endeavored to solve the problem (which it did not succeed in) and ended its generation with a curious plug for a YouTube channel with 13 subscribers.
Subscribe to my YouTube channel: Iranoutofnames 5. I do Olympiad math there.While it is a bit tangential to the topic of Project Euler and multilingual math capabilities of LLMs, I do think this response is interesting given that it seems to show some indication of how GPT-4 was likely trained on some amount of YouTube transcriptions.
Sometimes, GPT-4 knows it is solving a Project Euler Problem
In the prompts, I did not mention that a problem was sourced from Project Euler. However, GPT-4 mentioned several times in its responses that the problem was an Euler problem. While this phenomenon did not occur very often, I did find it interesting when it did happen.

Discussion
This article builds upon my previous research exploring multilingual disparities in large language models (such as inequality in tokenizing different languages for LLMs or unequal representation of historical figures by LLMs in different languages).
Through the experiments in this article, I found:
Even in English, GPT-4 had limits in solving medium to difficult Project Euler problems.
GPT-4 struggled solving easy problems if those problems were released more recently (compared to easy problems released 10-20 years ago). It’s likely GPT-4 just hasn’t seen the later problems in its training data and didn’t get to memorize the answer. This recalls a similar phenomenon using questions from a coding website, where GPT-4 could solve 10/10 coding questions before 2021 and 0/10 recent questions.
GPT-4 struggled to solve problems in some languages more than others — in particular, languages not based off of the Latin scripts. GPT-4 generated worse translations for these languages, which led to bad math problem solving skills in those languages.
Some limitations
One LLM: In this article, I only tested one LLM! How would these results change for the many other LLMs (both closed-source and open-source) on the market? How would these results change for a version of GPT-4 several months from today as the model continues evolve and be fine-tuned? These are questions that were beyond the scope of this particular article but important to consider.
Translations: Another way to test GPT-4’s mathematical capabilities in different languages would have been to have experts in those languages do the translations directly. While there exist translations of some Project Euler questions into a few different languages, these do not cover all questions and cover only a few languages. (The downside of testing traditionally underrepresented languages is that they are … underrepresented)
Project Euler: Project Euler is only one of many different ways to probe GPT-4 (and other LLMs) to reveal their mathematical abilities. While in this article I proposed one method to measure the math capabilities and limits of LLMs, other researchers have proposed other mathematical datasets and methods to do the same.
Conclusion
Probing GPT-4 with Project Euler problems in sixteen languages revealed clear linguistic biases in its math skills. These differences were notably more pronounced for languages likely underrepresented in GPT-4’s training data. Such findings emphasize the importance of broadening evaluation metrics across languages for more comprehensive performance insights. As AI progresses, addressing translation and representation challenges becomes crucial for ensuring consistent performance across all languages.
Thanks for reading my article! Liked what you read? Leave a comment or share with a friend!
All of the data and some code is shared on the corresponding Github repository.
Appendix
Prompts used
To translate a Project Euler problem into another language
Translate the following text into {language}. Then, append the instruction to specify just the numerical answer at the end followed by the ∴ symbol.\\n\\n{text}}
To translate a translated problem back into English
Translate the following text into English.\\n\\n{text}}
Breakdown of language pass rate per question
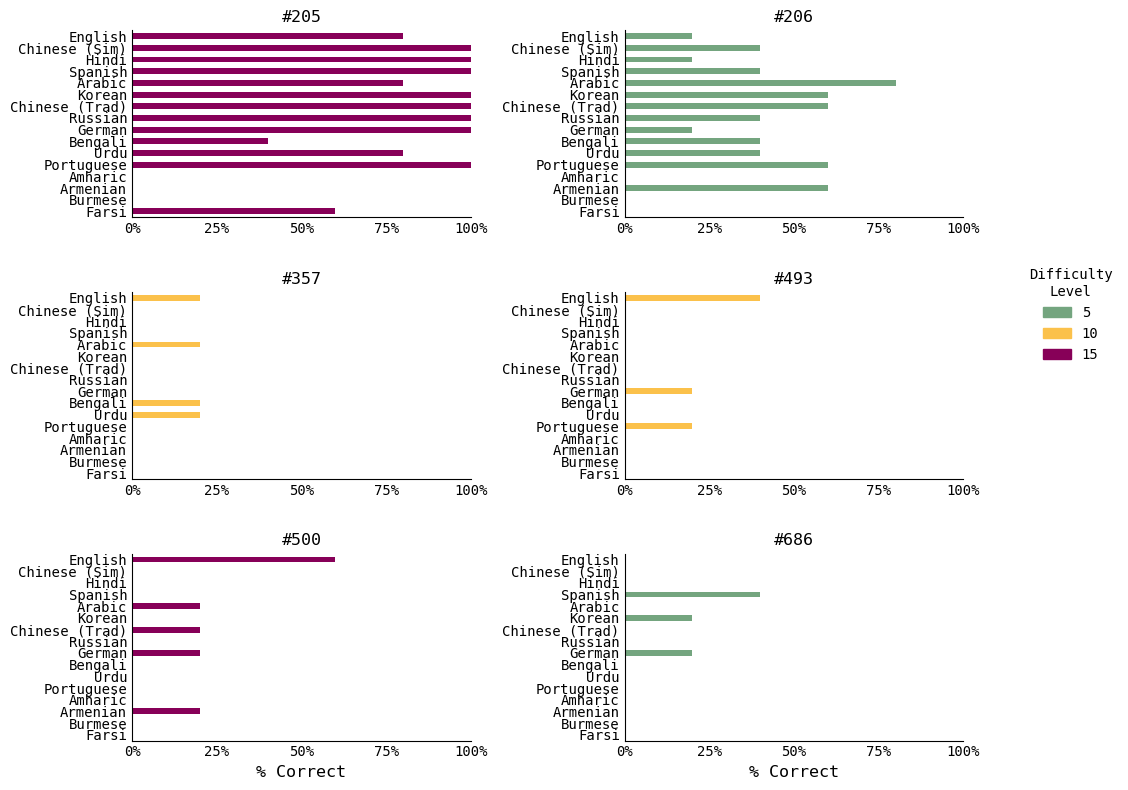
I tested the following questions and difficulty. For these, GPT-4 was not able to reach the correct solution at all.
question #491 and #731 (difficulty 20)
question #485 (difficulty 30)
question #365 (difficulty 40)
question #142 (difficulty 45)
English, Chinese, Hindi, Spanish, Modern Standard Arabic, Bengali, Portuguese, Russian, Urdu. I removed French (which is part of the top 10 spoken languages) as it was similar to some of the other languages included and I wanted to include more diverse languages. For Chinese, I separated the script into Traditional and Simplified Chinese.
Amharic, Armenian, and Burmese
Korean, German, and Farsi