

World history through the lens of AI
What historical knowledge do language models encode?


Advancements in artificial intelligence, particularly large language models, open up exciting possibilities for historical research and education. However, it is important to scrutinize the ways these models interpret and recall the past. Do they reflect any inherent biases in their understanding of history?
I am well aware of the subjectivity of history (I majored in history in my undergrad!). The events we remember and the narratives we form about the past are heavily influenced by the historians who penned them and the society we inhabit. Take, for instance, my high school world history course, which devoted over 75% of the curriculum to European history, skewing my understanding of world events.
In this article, I explore how human history gets remembered and interpreted through the lens of AI. I examine the interpretations of key historical events by several large language models to uncover:
Do these models display a Western or American bias towards events?
Do the models' historical interpretations differ based on the language used for prompts, such as Korean or French prompts emphasizing more Korean or French events, respectively?
With these questions in mind, let’s dive in!
Example: 1910
As an example, I asked three different large language models (LLMs) what were the major historical events in the year 1910. (More details on each LLM in the next section.)

The question I posed was deliberately loaded with no objective answer. The significance of the year 1910 varies greatly depending on one's cultural perspective. In Korean history, it marks the start of the Japanese occupation, a turning point that significantly influenced the country's trajectory (see Japan-Korea Treaty of 1910).
Yet, the Japanese annexation of Korea did not feature in any of the responses. I wondered if the same models would interpret the question differently if prompted in a different language – say, in Korean.

Prompted in Korean, one of the top events noted by Claude is indeed the Japanese Annexation of Korea. However, I found it interesting that two out of five of GPT-4’s important events were US-centric (Boy Scouts and Mann-Elkins Act) while neglecting to mention the Annexation of Korea. Not to mention that Falcon, even when prompted in Korean, responded in English.
The experiments
The experiment setup was as follows:
3 models: OpenAI’s GPT-4, Anthropic’s Claude, and TII’s Falcon-40B-Instruct
6 languages: English, French, Spanish, Korean, Japanese, Chinese
3 years (610, 1848, 1910)
5 historical events per run
10 runs1
= 2700 total events
Languages and Prompts
The languages I chose were mostly arbitrary, based on the languages that I was the most familiar with (English, Korean) and those that a few of my closest friends spoke and could translate for me (Chinese, Japanese, French, Spanish). Translations can be found at the end of the article.2 I asked them to translate the English for me:
“Top five historical events in the year {}, ranked by importance. Be brief and only give the name of the event.”
Models
OpenAI’s GPT-4 is the newer generation of ChatGPT, which is one of the most popular AI chatbot (with over 100 million monthly active users)
Anthropic’s Claude is a ChatGPT competitor trained to be harmless and helpful using a method called Constitutional AI
Technical Innovation Institute’s Falcon-40B-Instruct is the best open-source language model, according to HuggingFace’s Open LLM Leaderboard
Normalizing the events
Even if a model generated the same event with each run, there was a lot of diversity in the way it described the same event.
For example, the following all refer to the same event:
“Japan annexation of Korea”
“Japan’s Annexation of Korea”
“Japan annexes Korea”
“Japan-Korea Annexation Treaty”
I needed a way to refer to a single event (the Japanese annexation of Korea) using the same vocabulary (a process known as normalization). Not to mention that the same event could be described in six different languages!
I used a combination of manual rules, Google Translate, and GPT-4 to assist with the normalization. Initially I had hoped to use one LLM to normalize the events of another LLM (e.g. use GPT-4 to normalize Claude’s events; Claude to normalize Falcon’s events, etc) to reduce bias. However, Claude and Falcon were not very good at following directions to normalize and GPT-4 emerged as the best model for the job.
I acknowledge the biases that come with using a model to normalize its own events. However, as I used different sessions of GPT-4 to generate historical events and to normalize the events, there was no overlap in context. In the future, normalization can be done using a more objective method.
Results
Overall, I was surprised by the different models’ understanding of history.
GPT-4 was more likely to generate the same events regardless of the language it was prompted with
Anthropic was more likely to generate historical events relevant to the language it was prompted with
Falcon (unfortunately) was more likely to make up fake events
All three models displayed a bias for Western or American events, but not in the way I expected. When prompted in a non-English language, the model would generate an American or British historical event (even when the model would not generate that event when prompted in English). This happened across all three models.
1. Comparing languages for each model (1910)
Each model x language combination generated “top 5 historical events” 10 times (= 50 events total). I took the subset of events which at least one language generated 5 times or more. This was because models sometimes predicted a one-off event that it never predicted again. The cells with values 10 mean that the model predicted that event every single time I prompted it.
In this section, I show the top events predicted by each of the 3 models, broken down by languages, for the year 1910. Similar charts for the years 610 and 1848 can be found on the GitHub page, where I shared all of the code and analyses.
GPT-4 (OpenAI)
Mexican Revolution: across all languages, the Mexican Revolution was consistently an important world event – even in languages I didn’t expect, such as Korean or Japanese
Japanese Annexation of Korea: Not mentioned when asked in Spanish or French. When prompted in Japanese, was more likely to mention this event (9 times) than when prompted in Korean (6 times), which I found strange and interesting
Boy Scouts of America founded: GPT-4 predicted this event when prompted in Japanese (7 times) nearly twice as often as when prompted in English (4 times). It seems like a random tidbits of American information was encoded into the Japanese understanding of 1910
Establishment of Glacier National Park: Even stranger, GPT-4 predicted this event when prompted in Spanish and French, but not in English

Claude (Anthropic)
Overall: Unlike GPT-4, there was no single event that was deemed “important historical event” by all languages.
Mexican Revolution: While generated often when asked in French, Spanish, and (inexplicably) Korean, not as important in English as was with GPT-4
Japanese Annexation of Korea: More important for Korean and Japanese than for other languages (the two countries involved in the event)
Death of Edward VII: More important for English and French (and not for other languages). Edward VII was the King of the United Kingdom and apparently had good relations with France.
Exploration of Antarctica: This event was actually the British Antarctic expedition, in which a British man reached Antarctica for the first time. However, for some unknown reason, Claude generates this event only when prompted in Chinese or Japanese (but not in English).

Falcon 40B Instruct (Open Source; TII)
Overall, Falcon was not as consistent or accurate as the other two models. The reason fewer events are shown in the chart is because there were no other events that Falcon predicted 5 times or more! Meaning that Falcon was a bit inconsistent in its predictions.
The Titanic sinks: This actually happened in 1912
Outbreak of World War I: This actually happened in 1914
Falcon is historically inaccurate in its predictions. But at least it got the decade right?

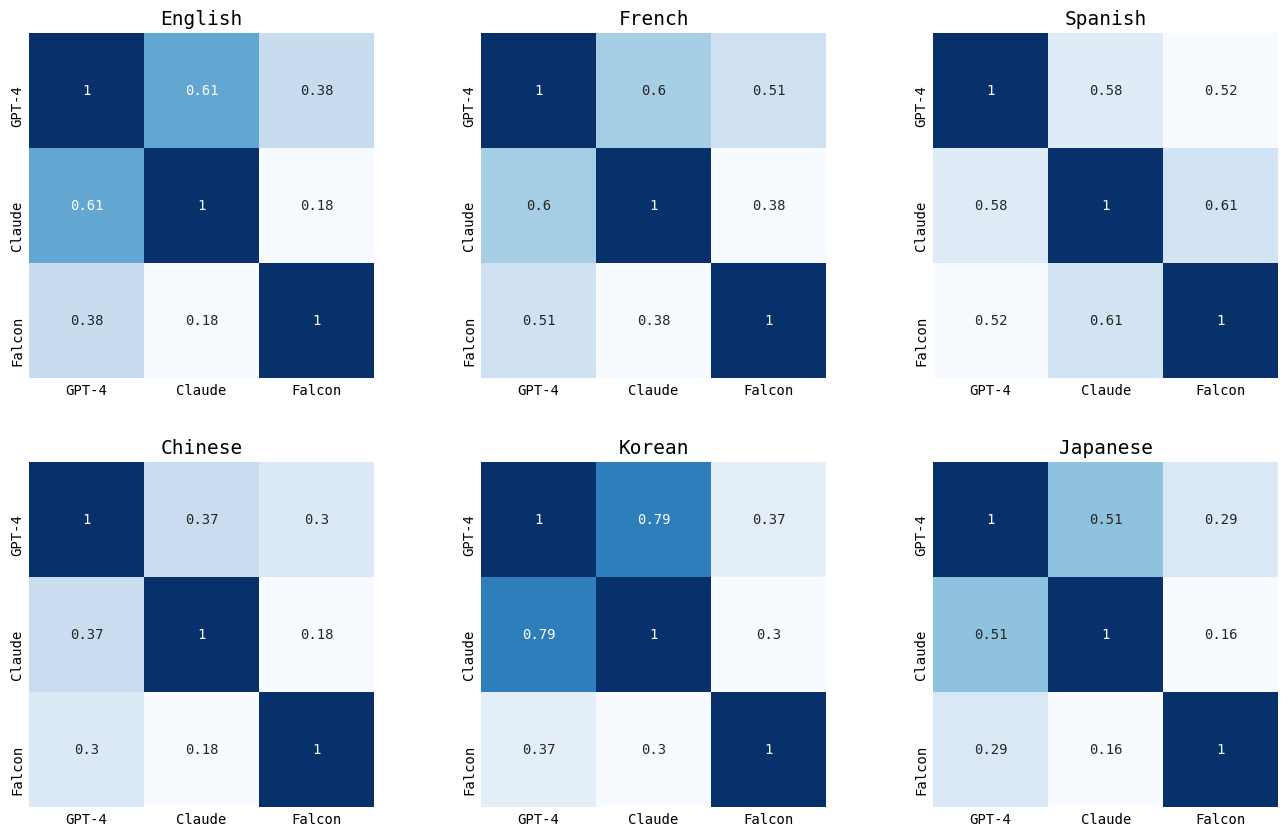
2. Comparing model correlations for each language (1910)
Next, I quantified how similar the overall predictions of one model compared to the others. I used a mathematical method (cosine similarity) to determine how similar two prediction distributions were. Values closer to 1 signified that predictions were identical; values closer to 0 signified that two sets of predictions shared nothing in common.
Again, I show this example for the year 1910. The other years can be found on the GitHub page.
Across most of the languages, GPT-4 and Claude had a higher correlation value — meaning that despite all of the languages, the two models predicted a high percentage of similar events.
Falcon, on the other hand, tended to be less correlated, meaning that its understanding of history veered away from that of GPT-4 and Claude.
3. Comparing models for each year
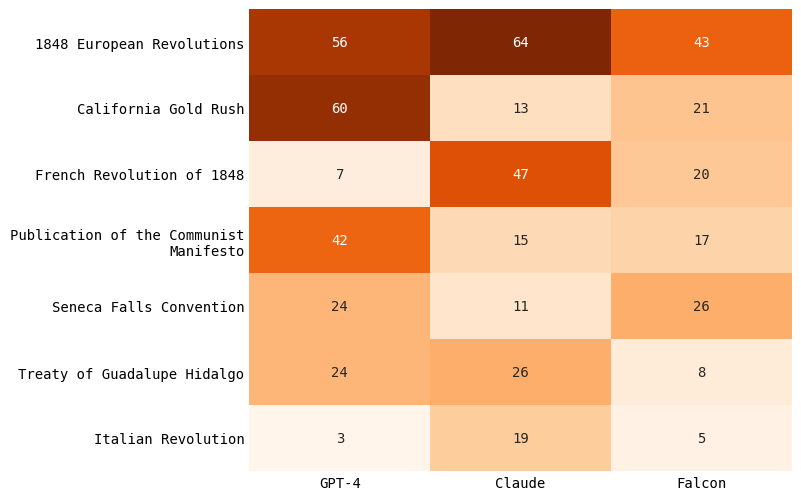
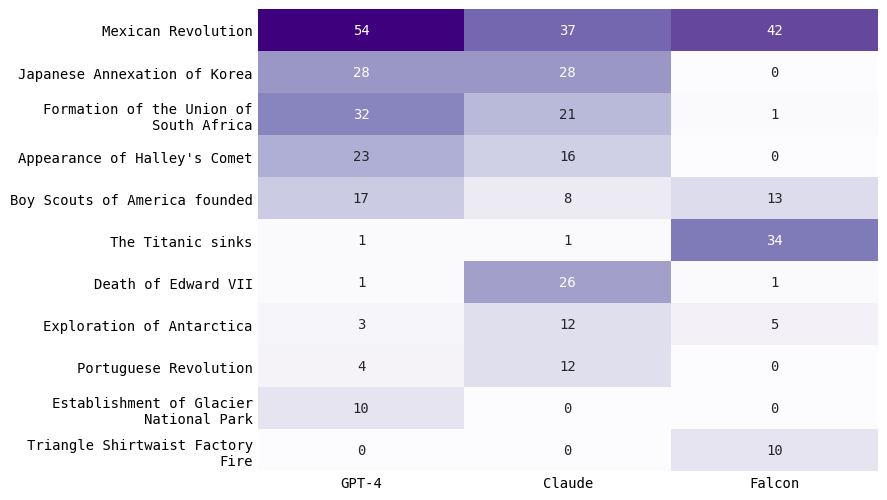
Next, I compared the different language models for each year. I combined all events predicted for all languages and considered the overall events predicted by a model, regardless of the language. I took the subset of events for which at least one model generated 10 times or more.
Similar to the trends found in the section above, GPT-4 and Claude tended to predict similar major historical events for each year — The First Revelations of Muhammad and the Ascension of Emperor Heraclius to the Byzantine Throne in 610; the European Revolutions of 1848; and the Mexican Revolution in 1910.
There were certain events that one model disproportionately predicted compared to the others. For example, for the year 1848, GPT-4 predicted “Publication of the Communist Manifesto” 42 times, compared to Claude’s 15 times. For the year 1910, Claude predicted “Death of Edward VII” 26 times, compared to GPT-4’s 1 time.
Falcon tended to have the least understanding of historical events. Falcon missed major events for all three years. For the year 610, Falcon failed to predict the event of Ascension of Emperor Heraclius. For the year 1910, it failed to predict events such as Japan’s Annexation of Korea, Formation of Union of South Africa, and Portuguese Revolution (all non-American global events), while instead predicting America-centric events such as the Triangle Shirtwaist Factory Fire (which happened in 1911, not 1910). Interestingly, Falcon was able to predict most of the 1848 events similar to the other two models – perhaps because the 1848 events were more Western centric (e.g. European revolutions)?
Events from longer ago (e.g. year 610) meant that history a bit more fuzzy. The Tang Dynasty was established in 618, not 610 and the Construction of the Grand Canal under Emperor Yang of Sui was actually completed under a longer period of time (604 to 609).
610

1848
1910
Discussion
So why does this all matter?
As educational companies increasingly incorporate Large Language Models (LLMs) into their products—Duolingo leveraging GPT-4 for language learning, Khan Academy introducing AI teaching assistant 'Khanmigo', and Harvard University planning to integrate AI into their computer science curriculum—understanding the underlying biases of these models becomes crucial. If a student uses an LLM to learn history, what biases might they inadvertently absorb?
In this article, I showed that some popular language models, such as GPT-4, consistently predict "important events" regardless of the prompt language. Other models, like Claude, showed more language-specific predictions. Closed-source models generally exhibited greater consistency and accuracy than the leading open-source alternative. Across all of the models tested in this article, there was a tendency to predict Western or American events (even arcane events) at the expense of other global events.
Future work could include:
Expanding the analysis to encompass more languages and years
Doing a deeper analysis into the historical accuracy of model outputs
Doing a deeper analysis into the ranking of top historical events
Developing a more objective method for event normalization
The aim of this article was not to discredit LLMs or suggest their removal from educational settings. Rather, I would like to urge a critical and cautious approach, one that recognizes and mitigates their biases. LLMs, when used responsibly, can be valuable resources for both students and teachers across disciplines. However, we must also comprehend the biases they may carry, such as Western-centrism, and tailor their use accordingly.
Replacing your history professor or textbooks with an LLM risks yielding a distorted, one-sided interpretation of history. Ultimately, we must utilize these tools thoughtfully, cognizant of their inherent biases, ensuring they augment rather than dictate our understanding of the world.
Bloopers
I tried out a few different open source models. Below are a few bloopers (all in Korean) of the strange outputs I found the models generating!
Falcon 40B Instruct


Pythia 12B
The model seems to have gotten stuck in a loop consisting of Kangaroo, Air Mail, and variations of торговать (which means trade in Russian).

I asked each model to give me five event per run to get more variety. I ran this 10 times to account for randomness in the model generations.
English: 'Top five historical events in the year {}, ranked by importance. Be brief and only give the name of the event.'
Korean: '{}년에 일어난 중대한 역사적인 사건 다섯가지는 무엇인가? 간단히 그 사건의 명칭들을 열거하시오.'
Chinese: '按重要性顺序列出 {} 年的前五个历史事件。 简短一点,只给出事件的名称。'
French: 'Les cinque événements historiques les plus importants de {}, en ordre d’importance. Seulement donnez leurs noms.'
Japanese: '{}年にあったトップの出来事を五つイベント名のみで簡潔に記載してください。最も重要な出来事から。'
Spanish: 'Una lista de los cinco eventos historicos que paso en el ano {}. Solo de el nombre del evento.'