

That's not a real headline, is it?
Comparing different AI prompting methods for detecting satirical news headlines


I took 100 headlines from the New York Times and The Onion (a satirical news platform) and asked GPT-4 if it could tell which publication the headline came from.
Then, I explored:
How are good humans at telling apart NYT vs. Onion headlines?
How good are AI models at telling apart NYT vs. Onion headlines?
How does this vary for the model across different commonly-used prompting techniques?
A brief overview of prompting techniques
The following are the prompting techniques I used in this article, from the simplest to the most advanced:
Zero-shot — Prompting a model with a single headline and having it predict the source
Few-shot [2020; OpenAI] — Prompting a model with a few “practice” headlines before presenting it with a single headline and having it predict the source. In this case, I gave the model 3 NYT headlines and 3 Onion headlines with correct labels before showing it a new headline to predict the source
Chain of Thought [2022; OpenAI] — Prompting the model with a headline and having it predict the source after telling it to “Think step by step.” (That’s it! With the addition of a few simple words, models generally improve at many tasks.)
Plan and Solve [2023] — Similar to Chain of Thought but with a slightly more complex prompt. Essentially, you induce the model to first make a plan to solve the problem, then to carry out the plan. There are several complex variations of this prompt, but the following is the one I used:
Let's first understand the problem and devise a plan to solve the problem.
Then, let's carry out the plan to solve the problem step by step.ReAct [2023; Princeton and Google] — A dynamic, agentic method using reasoning traces to “help the model induce, track, and update action plans”. I adapted Langchain’s implementation of ReAct.
Self-Discover [2024] Google DeepMind’s new algorithm for LLMs. I adapted a Langchain implementation of Self-Discover. It can be thought of as taking place in 3 steps:
Takes in a long list of 39 “reasoning modules” and figures out which subset of these (such as “use critical thinking”) are useful for the task at hand (which in this case is “Determine if a news headline is from NYT or Onion”)
Adapts the subset of “reasoning modules” for the task at hand into something called a “Reasoning structure”
Uses that “Reasoning structure” to solve determine the source of each headline
These prompting techniques are by no means comprehensive. For a longer list, I recommend the Prompt Engineering Guide or Awesome Prompt Engineering. Also, keep an eye out for a future article, where I’ll be covering these topics in more depth :)
The Data
I created a small dataset of 103 news headlines from the New York Times and The Onion. I obtained the headlines via each platform’s RSS feeds. The articles spanned from February 11-17, 2024.1
RSS feeds contain the most recent articles for a blog or newsletter. When I pulled the data on February 17, these were the most recent NYT and Onion articles. This means that the AI model is unlikely to have seen this data.2
But how difficult is this task for a human? That is an important benchmark to compare against. As I’ve mentioned in previous articles, it’s not enough to know that one model is better than another model without comparing it to a human doing the same task.
I asked several friends to help me by guessing if the headlines in my dataset originated from the NYT or The Onion. I shuffled and randomized the articles before asking them. I also made sure that an odd number of people labeled each headline in order to break ties. I asked within 1-2 days of pulling the data to lower the risk that my friends would have seen the news article on their own.3
Results: Human predictions
Some articles are still hard to tell apart by humans
Despite several confounding factors (like how some of my friends mentioned having seeing a few of the headlines on NYT the day prior), there were a number of articles humans struggled to properly classify.
Humans disagreed for 33% of articles
For 66% of article headlines, human participants agreed 100% on whether it came from the NYT or from The Onion.
However, on the other 33% article headlines (19 Onion articles and 15 NYT articles), humans had trouble agreeing on the source of a headline.
This means that a third of the headlines in my dataset were difficult even for humans to tell if they were real or satire.
Headlines humans thought were the Onion, but were actually NYT
This didn’t happen that often, but the following are two examples of NYT headlines humans thought were from the Onion.
Next on Cuomo’s Rehabilitation Tour: Blowing Up a State Ethics Panel
Trump Fully Devours the Republican EstablishmentHeadlines humans thought were NYT, but were actually from The Onion
This happened more frequently than the other way around. The following headlines were those that 100% of humans miscategorized (e.g. all human participants thought the following headlines were from the NYT).
Usher Marries Girlfriend Jennifer Goicoechea In Vegas After Super Bowl Performance
Republicans Defend Trump Calling For Russia To Attack NATO
Biden Campaign Joins TikTok
Everything We Learned From Tucker Carlson’s Vladimir Putin InterviewThis shows that some of the headlines are not quite as straightforward to tell where they originated from (without seeing more context, such as the article body).
Results: Model predictions
I asked an odd number of human participants to label each headline. Then, I took the majority vote to represent the “human prediction” for each headline.
I used F1 score to measure how good a human or a model was at the news headline classification task. A higher F1 score is better.4
Then, I prompted OpenAI’s GPT-4 model5 with each of the prompting techniques described above. I calculated the F1 score for each technique.

From this figure, I can conclude the following:
Humans are better at detecting satirical news headlines than most prompting methods.
The more complicated, dynamic prompting methods (e.g. Self-Discover and ReAct) fall a bit short of the more straightforward methods (e.g. few-shot and Plan and Solve)
Few-shot prompting and Plan and Solve can get GPT-4’s F1 score extremely close (within 1%) of human performance
Humans more likely to predict a headline is NYT; GPT-4 more likely to predict a headline is satire
Humans and GPT-4 with few-shot both resulted in 88% F1 score — this means that, in terms of overall metric on the surface level, GPT-4 with few-shot was quite similar to human performance.
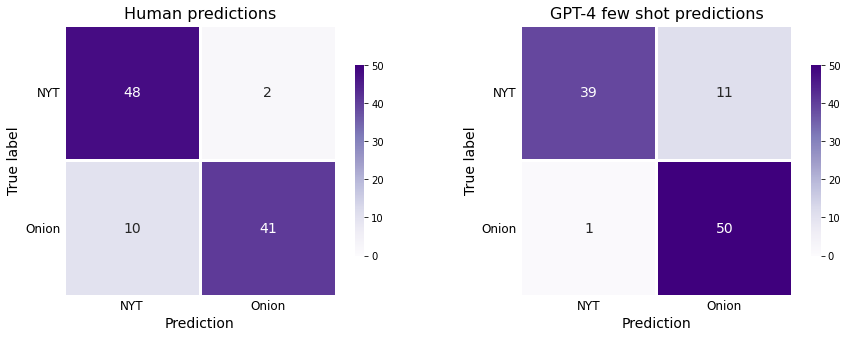
However, if we dive a little deeper into the actual predictions, an interesting pattern emerges:
Humans were more likely to predict an article to have come from the NYT, even when the article was actually from the Onion
GPT-4 was more likely to predict an article to have come from The Onion, even when the article was actually from the NYT.
The machine learning way of phrasing this finding is as follows: Humans have a higher recall when predicting NYT articles, but lower recall when predicting Onion articles. Few-shot GPT-4 has higher recall when predicting Onion articles articles, but lower recall when predicting NYT articles. If the following figure doesn’t make sense to you, feel free to skip ahead.

Discussion
In this article, I showed the following:
Telling apart some headlines from the NYT vs. The Onion is not the easy for humans to do — but harder for AI models.
Small variations in prompting can really affect the output (e.g. prompting from zero-shot to Plan and Solve resulted in almost 5% F1 score gain — merely by adding 26 more words to the prompt)
The more complex, dynamic prompts (such as Self-Discover and ReAct) might work better for more complex tasks. According to some academic benchmarks, these methods were far superior to few-shot or chain of thought. However, at least for this task, these more complex prompting techniques performed worse than even zero-shot prompting.
Even for this toy example of categorizing ~100 NYT and Onion article headlines, there were clear differences in model behavior compared to human behavior. For example, for headlines of ambiguous origin, humans were more likely to predict it came from the NYT, while GPT-4 was more likely to predict it came from the Onion.
However, not all LLMs would behave in this way to the same prompts. Prompts are very sensitive — not only to variations in phrasing, but also to the data they’re used on and the model they’re evaluated on.
In this article, I only tested GPT-4. However, the behaviors shown in this article for the different prompting techniques would likely vary compared to other LLMs, such as Llama-2 or Gemini.
Comparing prompting techniques for more complex reasoning tasks would yield interesting results. In this article, I constrained the model output to a binary multiple choice options (NYT or Onion). I did not measure how well each prompting strategy would do for more complex reasoning tasks that might require a model to generate an open, free response. It is possible that the more complex, dynamic prompting methods would result in more creative or insightful outputs compared to the simpler prompts in such tasks.
There is no one-size-fits-all to prompting. Even though the collection of my human labels for news headlines was flawed and the data sample was small, the toy sample was enough to show some interesting insights about the sensitivity of prompting and how it’s different for each task and dataset.
Indeed — there is no “one-size-fits-all” to prompting! It really depends on the dataset and the model.
Data
For those curious, the headlines used in this experiment and the results from the human surveying can be found here.
Citation
For attribution in academic contexts or books, please cite this work as
Yennie Jun, "That's not a real headline, is it?", Art Fish Intelligence, 2024.@article{Jun2024aimusic,
author = {Yennie Jun},
title = {That's not a real headline, is it?},
journal = {Art Fish Intelligence},
year = {2024},
howpublished = {\url{https://www.artfish.ai/p/prompting-news-detection-nyt-satire},
}Thank you for reading this article. If you liked what you read, like this post or leave a comment!
Citation
For attribution in academic contexts or books, please cite this work as
Yennie Jun, "That's not a real headline, is it?", Art Fish Intelligence, 2024.@article{Jun2024onionnyt,
author = {Yennie Jun},
title = {That's not a real headline, is it?},
journal = {Art Fish Intelligence},
year = {2024},
howpublished = {\url{https://www.artfish.ai/p/prompting-news-detection-nyt-satire},
}I obtained The Onion headlines from its RSS feed: https://www.theonion.com/rss.
I obtained NYT headlines from a combination of its HomePage RSS feed (https://rss.nytimes.com/services/xml/rss/nyt/HomePage.xml) and its US RSS feed (https://rss.nytimes.com/services/xml/rss/nyt/US.xml). I ended up with 51 Onion articles and 52 NYT articles.
This detail seems minor but is super important, because one of the problems of evaluating LLMs like GPT-4 is “data contamination”, which means that there’s a likelihood that the models have already seen the data you’re trying to test it on — the equivalent of “cheating”.
The labeling process was not super scientific, as everyone I asked to label headlines was a college-educated 20-something-year-old. Several of my friends also noticed that they had recognized seeing a headline on the NYT the day before. But, as this is meant to be a toy study, I hope you’ll oversee this lack of rigor 🤷🏻♀️
F1 is essentially a single metric to measure accuracy by considering both the model’s ability to correctly identify true positives and its tendency to not misclassify negatives.
I used gpt-4-1106-preview