

How my personal data collection practice evolved over the years
And why now is the best time to start your own

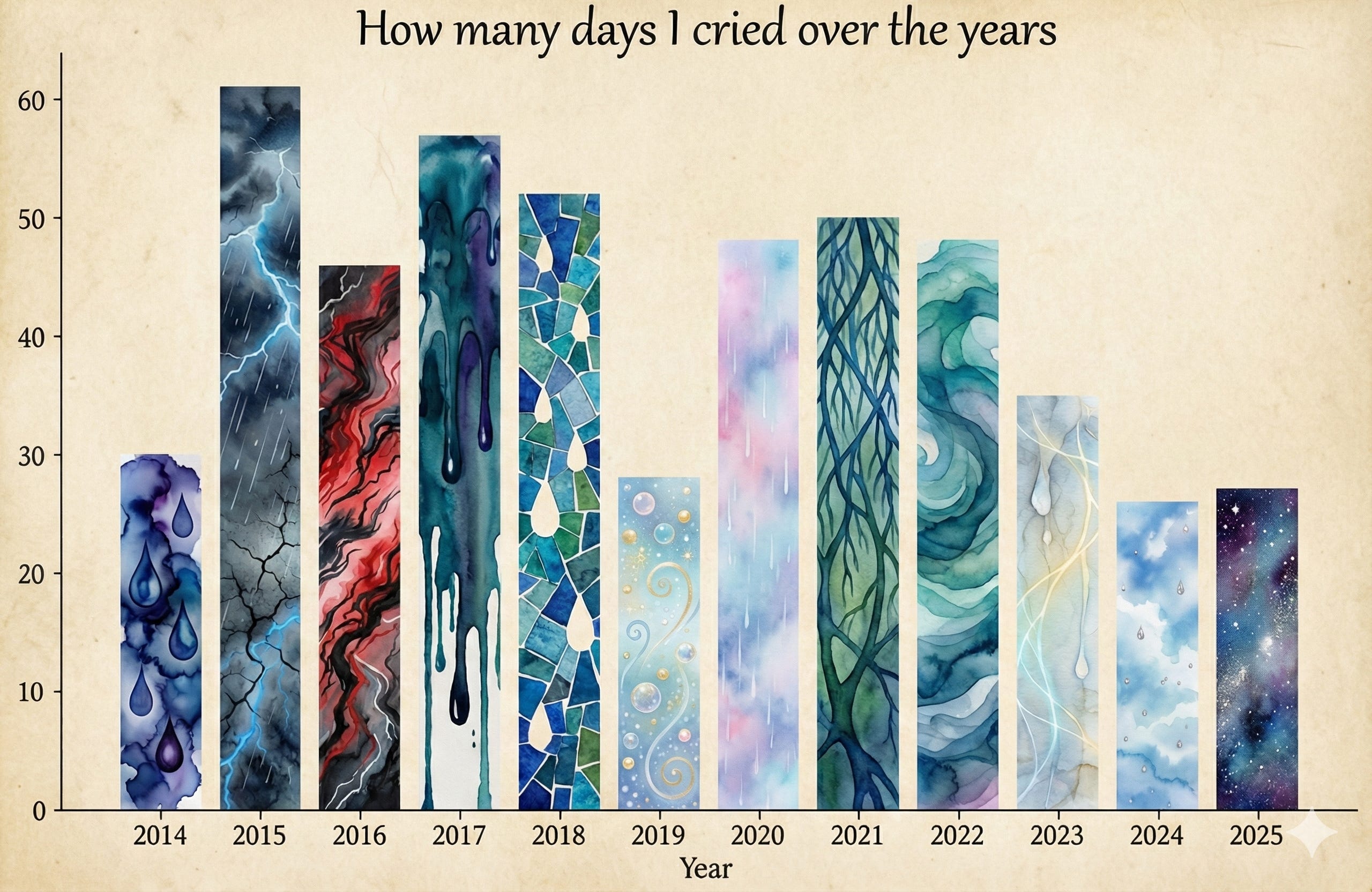
It all started with a few weirdly obsessive and slightly idiosyncratic questions about my daily life and habits. Questions like: “How often do I cry?” and “Can I predict when I’ll get sick?”
I started collecting personal data in early 2022 in the form of daily survey questions. This practice has evolved as I’ve iterated on everything from the survey content (quantity, specificity, and breadth of questions) to the tools I use.
In this article, I want to share this journey and what I've learned along the way.
Evolution of the Survey and Data Collection Process
Each year, I update my personal data collection survey. Here are some patterns I noticed over time:
Each year, I collected more data. The number of overall questions increased every year, peaking at almost 40 questions for the 2025 Survey. Interestingly, this number dipped a little for the 2026 Survey, so maybe somewhere between 30 and 40 is a sweet spot.
Questions became more open-ended and less structured. I originally started with a lot of structured data — that is, questions for which you pick one of several pre-defined options (e.g. “Which of the following exercise options did I do?”, “Did I cry? Yes/No”), or specify a numeric amount (e.g. “How many hours of sleep did I get last night?”). As the years went on, I began to introduce more and more unstructured data, or open-ended questions that can be answered using natural language (e.g. “Which friends did you see today?” or “What is one thing that made you feel alive today?”)
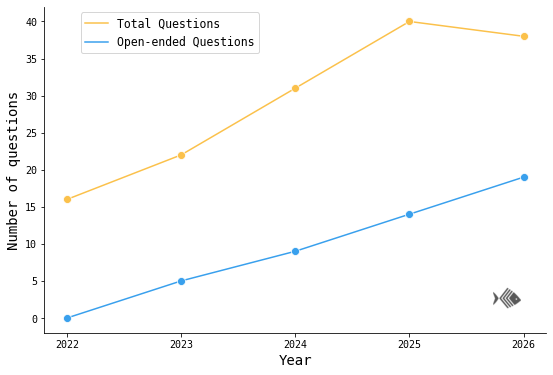
Questions became more diverse. More surface-level questions (e.g., which exercise, whether or not I cried) evolved into deeper ones (e.g., how did I feel, why I cried).
I iterated on the medium based on personal preference. I experimented a lot with different tools to collect my data. I first started with Google Forms because it was the most convenient, then I realized while camping for a week with no Internet that I couldn’t load the form on my phone. That gave me a lot of (maybe unnecessary) anxiety, so the year after, I switched to Jotform so that I could fill out the form offline. A few years later, I switched to Airtable because I ran out of storage on Jotform and I liked its customizability.
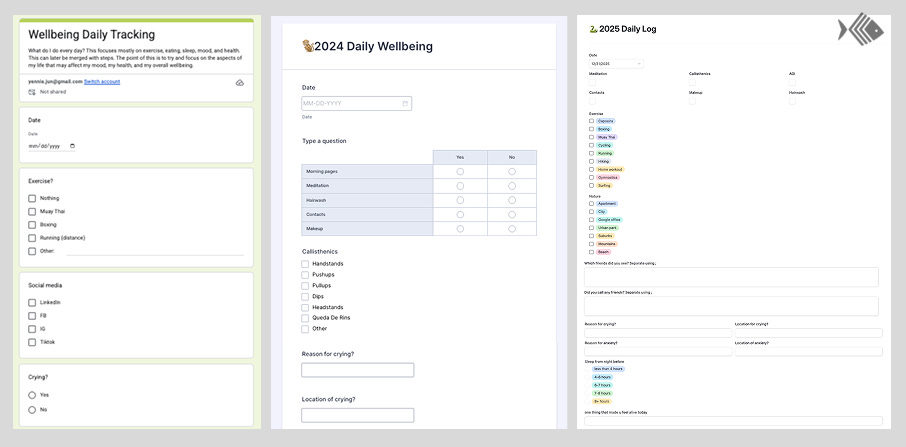
Evolution of the Data Analysis Process
When I first started analyzing my habits in 2022, I was obsessed with understanding my habits and patterns, such as when I cry, what makes me feel alive, and how my body signals illness. I was eager to dive deep into doing my own data analysis. I collected datasets from multiple sources, merged and cleaned the data, extracted salient features, and ran (simple) regression experiments. I even trained my own word embeddings at one point.
Last year in 2024, I began experimenting with dumping my data directly into AI tools (e.g. ChatGPT, Claude, Gemini) and having them do the data analysis part with me. I thought the tools had become good enough at coding and data analysis skills to entrust them with this task. What I found was that all of the major AI tools exhibited an (unhealthy) amount of hallucinations. My conclusion last year was that while it was an enlightening experiment, that it was probably safer to trust these tools with a grain of salt and to do some verification before blindly trusting results.
This year, I tried that process again, and as cliche as it must sound by now, I am astounded at how much these tools have improved (even as someone who works on improving Gemini for my day job!).
Now, not only can the tools do the data analysis, they can create beautiful HTML pages with insights, trends, and analysis points. Let me show you.
Some AI-Generated “2025 Wrapped” Reports from This Year’s Data
I kept things relatively simple compared to previous years in terms of data preparation. I only used my Apple Health and 2025 Survey data, and did some very basic data cleaning, such as manually fixing dates, merging data sources, and minor feature extraction.
I have to admit, I didn’t expect the results to be this good. I simply cleaned up my data and dumped it into Claude/Gemini/ChatGPT (I tried all 3). Each tool generated a stunning HTML report, complete with visualizations, trend analyses, and insights. The AI tools were particularly good at analyzing unstructured text data, finding patterns and insights that sometimes delighted and sometimes surprised.
Below are a few screenshots from some of the different AI-generated reports, each containing interesting insights and sometimes, a call to action. The reports varied based on the seed questions I asked the AI tools to focus on, such as my emotional state, health, or my general well-being.













Why You Should Start Collecting Your Own Personal Data
Compared to any time in the past, it is now incredibly accessible for any lay person to analyze their own data, even if you don’t know a single thing about Python, R, Jupyter notebooks, plotting libraries, word embeddings, or statistical analyses.
The real decisions are now around what data you want to collect, how much of it, how often, and in what form to best convey your actual lived experience. The AI tools at our disposal are so good at coding and visualizing that all you really need to do now is:
Collect data that matters to you
Think of good questions to ask about your own patterns and behaviors
There’s something uniquely valuable about self-reported survey data because it’s your own ground truth. When you report that you cried on a particular day, there’s no ambiguity, no inference needed. While fitness trackers and search histories can offer educated guesses about your state of mind or behaviors, survey data is unequivocal.
But more than that, collecting your own data means you have ownership over these insights. You’re an active participant in understanding yourself, not a passive subject of someone else’s analysis. Companies are already collecting data about you and drawing conclusions about your actions and habits (and sometimes those insights seem eerily accurate).
But the best insights come from explicitly writing your own story, which I encourage you all to reflect upon in the new year 😊
An important caveat: I dumped subsets of my personal data into public AI tools, which isn’t the most privacy-conscious approach. If you’re collecting sensitive personal data, consider using local analysis tools, API versions with better privacy controls, or be thoughtful about what you share. For me, the insights were worth the tradeoff, but that’s a personal decision everyone should make consciously.
Such a fun read! Wednesdays...
As always, thanks for the great data science insights with human touch ❤️
- Erika