



LLM vs LLM: Codenames tournament
A mini multi-agent competition among 3 different LLM agents


Introduction
LLMs are good at many things, and one of those things is playing games. People have used LLMs to play all sorts of games such as Minecraft, Chess, murder mystery games, Werewolf, and the NYT Connections puzzle. (For a more comprehensive list, you can refer to this survey.)
Most of the examples above show LLMs playing games either against themselves or against humans. But, how well do LLMs play games against other LLMs?
In this article, I show the results of three different LLMs competing against each other in the popular board game, Codenames, which challenges players to find patterns among seemingly unrelated words.
Codenames
For those unfamiliar with it, Codenames is a board game created by Vladimír Chvátil. The game pits two teams (typically Red and Blue) against each other.
Each team has a spymaster who gives single-word clues that are meant to point to multiple words on a 5x5 board of words. The other players on the team must then guess their team’s words while avoiding words that belong to the opposing team. Only the spymaster knows which words are assigned to each team.
For example, a Red team spymaster might offer the clue "WHITE 3," hoping that their teammates will select LIGHT, IVORY, and CHOCOLATE.

The aim is to give clues that allow your team to guess its words without mistakenly picking the other team's words, neutral words (the black words), or the Assassin word (the black word with the gray background). Choosing the Assassin word ends the game and causes your team to lose. The first team to guess all of their words wins.
AI and Codenames
Researchers and AI enthusiasts have already set up frameworks for “playing” Codenames using AI. The Codenames AI competition began in 2019 to test automated agents’ ability to play the game — several years before LLMs were even a thing. Word embeddings like Word2Vec and GloVe, used in those early competitions, were surprisingly effective at playing Codenames by simulating the clue-giving and guessing process. (For context, word embeddings are numerical representations of words, and are an early precursor to today’s LLMs.)
Recently, the competition was extended to include LLMs in Codenames AI for LLMs. In this setup, the LLMs on both teams come from the same base model (e.g. GPT-4 playing against GPT-4).
In my experiments, I decided to mix things up by having teams of one LLM play against teams of a different LLM.
Experiment setup
I compared three different systems: OpenAI’s GPT-4 (gpt-4o-2024-05-13), Anthropic’s Claude-3.5 (claude-3-5-sonnet-20240620), and Google’s Gemini (gemini-1.5-pro). (Note: I decided not to use the latest o1-preview model due to its higher cost.)
Each LLM combination played 24 matches against one another.
To keep things simple, I used the same prompt for all models and avoided any attempts to optimize prompts for specific models. I used the prompts and frameworks forked from the Codenames GPT repo. Each game was composed of four LLM instances — LLM1 Spymaster and LLM1 Guesser on one team, and LLM2 Spymaster and LLM2 Guesser on the other team.
Two turns in a single game might look like the following:
First, the Red team’s spymaster would issue a clue. Then, the Red team’s guesser would select words based on that clue. In this case, both members of the Red team are GPT-4.

In the next turn, the Blue team’s spymaster would issue a clue, and then the Blue team’s guesser would select words based on that clue. Here, both members of the Blue team are Claude.

Results
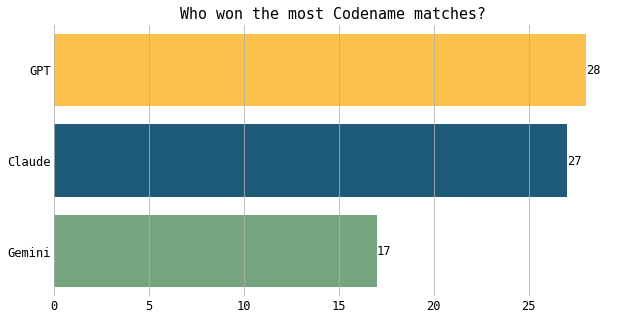
Who won the most matches?

The chart below breaks down the winners across 24 games for each LLM pairing. In general, GPT-4 and Claude were closely matched, though GPT-4 tended to win slightly more often . Both GPT-4 and Claude consistently outperformed Gemini.
In terms of total victories, GPT-4 and Claude won the most games.
Who chose the most Assassins?
In Codenames, the “Assassin” card should never be selected. If the Guesser accidentally chooses the Assassin, the game ends, and that team loses. So, the clues must be clear and unambiguous to avoid selecting the Assassin.
When a team picks an Assassin, it suggests that the spymaster and guesser aren't on the same page regarding the clues and the words on the board.
Selecting fewer Assassin cards is key to success. In my experiments, GPT-4 selected the most Assassin cards, while Gemini selected the fewest. This suggests that although GPT-4 won more games, Gemini may be more cautious with its guesses and clues.

Game lengths
LLMs took significantly more turns to complete a game of Codenames (up to 9x more) compared to traditional word embeddings.
Across all 3 LLMs, the models completed a game in an average of 13.5 turns. This number excludes games that ended prematurely due to an Assassin being chosen.

On the other hand, older word embeddings like GloVe needed as few as three turns to finish a game. Other experiments showed that combining word embeddings with human judgments could complete a game in as few as 6 turns.

This suggests that while newer models are more sophisticated, they might be less efficient at this particular game compared to simpler, older methods. LLMs tend to play conservatively, with LLM-based spymasters often only providing clues for two or three words at a time. In contrast, humans and word embeddings might offer more abstract or creative clues that could end the game in fewer turns.
Discussion
Codenames is just one of many games that people are experimenting with having LLMs “play”. We’ve gone from making LLMs do things that humans do for work (like coding or customer service) to, increasingly, making LLMs do things that humans do for fun (like playing games).
In my experiments, I explored how well LLMs perform against each other in a specific game-based setting. Games offer a way to test LLMs’ reasoning, strategy, creativity, and cooperation — skills we may want them to develop further to better assist us in other tasks.
I think we will likely see more of these kinds of game-based settings for testing LLMs. LMSYS’ Chatbot Arena is related to this idea, where two LLMs are judged by humans to see which gives the better response to a prompt — essentially, a game of “who gives the better answer to a question.”
AI agents also show promise in helping develop better games in the future, as seen in recent multi-agent frameworks for automating game development.
However, having fun (much like creating art) is a fundamentally human endeavor. I don’t want to get too much into the philosophical weeds about whether AI can have fun or create art or be creative. Ultimately, these games are meant for humans to enjoy, and AI can hopefully assist us in creating richer experiences without replacing the joy of playing them ourselves.