

2024 in review: my reflections on AI
My thoughts on some things that happened this year and what I'm excited for next year


Intro
As 2024 draws to a close, I want to reflect on the events in AI this year and share my thoughts on what lies ahead.
Looking back to the start of the year — to the projects I was working on, the papers I was reading, the topics going viral on Twitter, the headlines in the news, and all of the things (AI-related) I was spending my time thinking about — I realize how much this space has changed!
Two weeks ago, I attended NeurIPS, one of the largest AI and machine learning conferences, with over 16,000 attendees this year. The sheer breadth and depth of research there was overwhelming, and it was exciting to meet many of the people behind the papers I’ve read.
I’ll cover some key takeaways later, but I left the conference with three main thoughts:
How much progress there already is: The research at NeurIPS represented only a small subset of published AI work, not counting other conferences, unpublished work, or industry research.
Most of the research hasn’t reached the public yet in terms of applications, implications, or general awareness.
A portion of the research is already outdated.
How can research be so new that most people don’t know about it, yet already outdated? This contradiction shows how fast the space of AI is moving. It also shows how much hype exists in some areas, while other areas receive little public attention.
The conference reminded me how vast this field really is. While wandering around the poster sessions (which spanned multiple rooms across multiple days), I was struck by how small (spatially and physically) my corner of AI was compared to the breadth and depth of others’ research.
My work focuses mainly on LLM evaluations and benchmarks, which is a tiny slice compared to the broader landscape: architecture optimizations, computational biology, neuroscience, robotics, physics-based modeling, and many more domains filled with unfamiliar terms and acronyms. While LLMs still dominated in terms of popularity, the conference was a great reminder that LLMs are only just one small subfield of AI.

Reflections on 2024
In 2024, I spent most of my time working on and thinking about generative AI, LLMs, and benchmarks and evaluations. From that perspective, here are some of my reflections:
A flourishing of smaller models.
This year, the gains from ever-larger models began to show diminishing returns. Larger isn’t always better, and we saw a surge in smaller yet high-performing models, such as Google’s Gemma (available in 2B and 7B parameters), Microsoft’s Phi-3-mini (3.8B parameters), and GPT-4o mini. These models are fast, efficient, and much cheaper than their larger counterparts. Methods like knowledge distillation (training a smaller student model using a larger teacher model) and quantization (using fewer bits per parameter) have made these models more capable.

Reasoning models that use more inference compute: thinking and agentic models
Traditionally, most of the compute for an LLM was spent on training. Now, more and more compute goes toward inference (the part where you are actually using/calling the trained LLM).
A new paradigm is emerging where models use additional compute at inference time — for example, by using longer prompts with multiple examples or sampling the model multiple times and taking a “majority vote” answer.
The diagram below compares OpenAI’s o1 model (nicknamed “Strawberry”) to more traditional LLMs, but the concept refers to other such models in this space. (For those interested, see Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters)
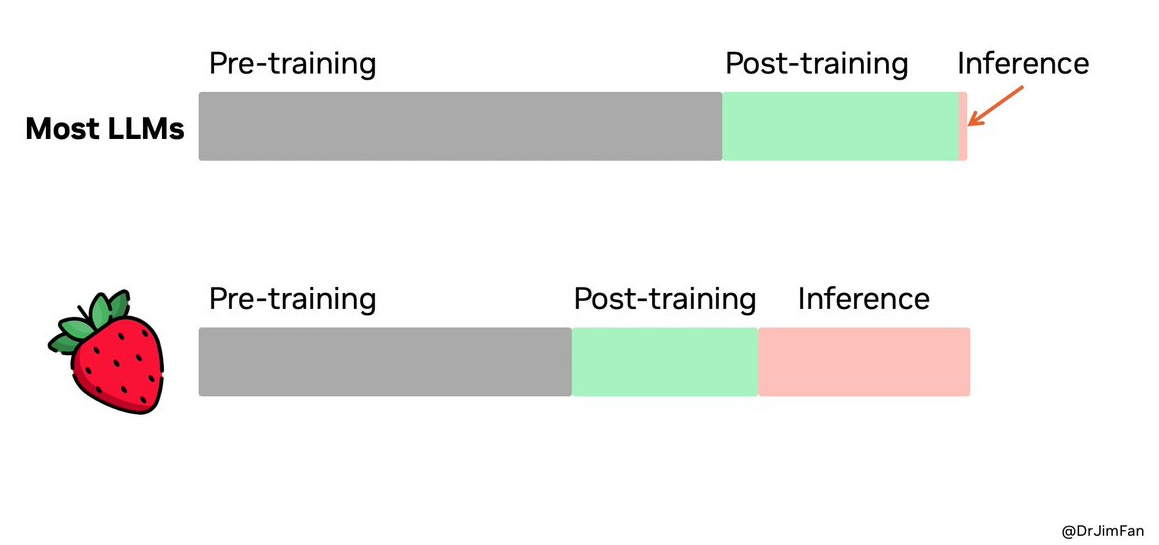
This approach appears in two main ways:
Agentic Models: Here, inference-time compute scales up through AI agents, or LLMs that can call external tools (such as searching, browsing, running Python, or invoking smaller specialized LLMs). AI agents can orchestrate complex workflows, often through iterative model calls (like a loop with an LLM that calls search). I’ll talk more about agents later, but they often require more compute at inference time due to extensive instructions or iterative model calls.
Thinking Models: These models (e.g., OpenAI’s o1 and o3, Google’s Gemini 2.0 Flash Thinking Mode) are trained to output detailed reasoning steps before giving a final answer. They often produce long, meandering “streams of consciousness” before arriving at an answer.

More “well-rounded”, general-purpose models
Models are becoming more versatile. They handle multiple modalities and languages with improving performance. There are multiple AI systems now which you can speak to, and which will speak back to you in a natural way. You can snap a picture or livestream a video of your surroundings (like Google’s Project Astra, “a universal AI assistant”), and the AI system can describe what’s happening. Some of these systems can even code full web apps. AI is evolving into an ensemble of capabilities rather than a single-purpose model.
AI-generated videos
I actually can’t believe it was only February of this year that OpenAI released Sora, an AI model that creates video from text instructions. Since then, Meta released MovieGen in October, which not only creates video from text but also edits video and generates soundtracks. In December, Google released Veo2, a video generation model “which convincingly simulates real-world physics as well as a wide range of visual styles”.
The following is one of the videos created by Veo (which is available on waitlist on VideoFX).
I find the speed of this progress incredible and astounding. I find the speed of this progress incredible and astounding. If you haven’t yet, I urge you to check out the links and watch some of the videos for yourself!
Looking forward to 2025
I’m both excited and apprehensive about the AI landscape in the coming year. Reflecting on the past year and attending NeurIPS inspired me with the sheer amount of research that happened in 2024. Here are some areas I’m paying close attention to for the upcoming year:
Development of more difficult benchmarks and evaluations for AI systems
While new AI capabilities are exciting, we need tougher benchmarks to measure progress (and, in some cases, regress). Models are improving so fast that popular academic benchmarks (like MMLU and MMMU) are quickly saturated or outdated. There is a constant need for more challenging and difficult evaluations.
Some benchmarks are still challenging for state-of-the-art models, such as:
Frontier Math and AIME for complex mathematical reasoning.
ARC-AGI for visual pattern matching and reasoning.
These evaluations can take the form of tasks that are easy for humans but still hard for models, like with ARC-AGI. For example, the following is an example from ARC-AGI that is pretty easy for most humans but that leading models like OpenAI’s o3 fails to answer correctly.

These evaluations can also take the form of tasks that are time-consuming or difficult for humans, or within the realm of “experts”, such as the difficult mathematical reasoning questions.

In the next year, there will be more evaluations that cover all of these grounds, and more: those that are easy for most humans but still hard for models; those that are hard for both humans and models; those that are more niche and expert-focused; and those that mix reasoning with multiple modalities (such as audio and video, in addition to text). Additionally, I believe there will likely be greater emphasis on assessing AI systems end-to-end — especially agentic and user-experience focused.
At NeurIPS, I met a physicist who was working on physics-based modeling, which is a totally different area of AI from me. When I told her that I was working on LLM evaluations, she said, “Evaluations? It’s so unscientific, I don’t know if we can even call it a science.” Hopefully, in the coming year, we will see more robust, statistically grounded approaches to evaluations (building upon recommendations from this November for making evaluations more statistically robust).
Continued efforts on agentic behavior
AI agents can be as simple as search-based chatbots or as complex as end-to-end automated coding systems. Some examples include PR-Agent, which automatically reviews code, and Lindy, which automates workflows such as replying to emails. While there’s plenty of hype, there’s also real substance here. I’m excited for the ongoing work on agents and real-world applications that solve real user problems that will continue to be developed in the new year.
This Github page contains a more comprehensive list of both open and closed source AI agent projects for those interested in a more comprehensive list. I also refer readers to Interconnects.AI’s article on the AI Agent Spectrum and The Batch’s article on agentic design patterns.
Ongoing questions about alignment and safety
At NeurIPS, several of the talks that I found the most compelling were centered around questions of “Who are we aligning the models to? Whose values, intentions, and preferences? Determined how and by whom?”
These questions have both technical and human-centered aspects. There are many open questions here about the best way for models to come to decisions, especially for controversial or open-ended topics which may have more than one right answer, or no right answer at all.
I doubt that any of these questions about alignment (e.g., whom to align with, whose values to follow) will reach a consensus anytime soon. However, I do look forward to more conversations and engagements from researchers, industry practitioners, and the general public around these questions.
Additionally, as AI becomes a mainstream technology used not just by those within the technology field but by all sectors and users, there will be increased scrutiny on safety and fairness. Real-world deployments can have tragic consequences, such as when an AI chatbot encouraged the tragic suicide of a teenager. These systems also affect different demographic groups differently, requiring more attention to bias and equity.
Many researchers are currently tackling safety from multiple angles: auditing datasets, improving training practices, and debiasing evaluation data. I expect more progress here, including best practices for end-to-end systems and effective mitigations.
Other areas
There are so many other areas I am also excited for, but if I wrote about them this post would get incredibly long: model interpretability (such as Anthropic’s use of sparse autoencoders), watermarking technologies (such as Google’s SynthID, which adds statistical watermarking signals to AI-generated content), and the ongoing convergence of generative and embodied models in robotics.
Some final thoughts: making sure not to lose the “human” part of AI research
At NeurIPS, I learned about an organization whose goal is to automate science end-to-end. Their wet labs run on robotics controlled by an LLM agent. The LLM agent would eventually control the entire end-to-end process: generating hypotheses, running experiments, analyzing data, and writing papers. Humans would be used mostly for quality control. I asked if it wasn’t still important for humans to be part of the hypothesis process, and the representative disagreed, saying, “Should humans even be the ones asking the questions anymore?”
While everyone else around me was excited by these developments, I could not help but feel worried and afraid. Things started to feel a lot more dystopian to me. On one hand, it is not surprising that we are moving in this direction, what with recent developments such as Sakana’s AI Scientist, which uses foundation models to “automate the entire process of research itself”, and recent papers like Can LLMs Generate Novel Research Ideas?.
However, I worry for the day when humans won’t be part of these systems anymore. If humans are not the ones asking the questions, what are we really needed for?
This reminds me of debates about AI and creativity. Can AI truly match human creativity? For me, creative pursuits such as writing, music, and art reflect the human soul. I often think of Ted Chiang’s essay, which explores these themes, reminding us of the necessary human essence in creativity.
All of this to say is that, despite all of the progress that has happened and continues to happen in the AI space, it is important not to lose sight of the human within the system. Paraphrasing a quote by Professor Yejin Choi, AI should be built, not to be served by humans, but to serve humans.